When adding new features to software, you can add a Feature Flag. If set to true, it uses the new feature, false and it doesn’t. This allows a quick roll-back feature by tweaking this value rather than releasing a new software update. However, it makes the code more complicated due to branching paths.
When all users are now using the new feature, when do you remove the code? Obviously it should be removed once all users are switched over and happy with the new functionality, but the work needs to be planned in, and what is the urgency? Project Managers will want new projects that add value, not deleting redundant code.
One of our most experienced developers posted a rant about feature flags. He pointed out there was no guidance on when to use feature flags. Do all new features get feature flags? What if it depends on a feature that already has a feature flag? Do Software Testers test each combination to make sure all code paths are supported? Is it clear which configurations are deployed on live since this should have priority when it comes to testing? By default, our Test Environments should match the config of a typical Live Environment. However, we often find that the default is some configuration that is invalid/not used.
It’s not always possible to “roll back” by switching the feature flag off. This is because to implement the change, you may have needed to refactor the code, or add new database columns. Changing the feature flag back to “off/false” just stops some new code being called, but not all new code changes (the refactored parts). So if the bug is with the changes even with the flag off; then it is still a problem.
It was also discussed that some people used our Configuration Tool for actual configuration and others were using them as Feature flags, and maybe we should have separate tools for Configuration and Features.
Feature flags cause maintenance problems. It needs to be tested on/off when implemented, then if you want to remove it, then that needs to be tested too. If you leave it in, then it’s always going to be questioned if code in that area is used/needs testing. How do you prioritise removing the code; does it belong with the team that initially created the feature? What if the team has moved on, or split?
Another developer brought up an example of how a bug existed in two places but the developer that fixed the issue was only aware of one path, and didn’t know about the other which required a feature flag to enable.
He also questioned if it is more of a problem with our process. Other companies may have quicker releases and are more flexible to rollback using ideas like Canary Deployment. Our process is slow and relies on “fix-forward” rather than rollback.
Things to consider:
What actually gets feature flagged?
When is the conditional code is removed from the codebase
Effect of the “Cartesian Explosion” of combination of flags on unit tests and test environments
For my home internet and mobile sim, I have Virgin Media and a Virgin Mobile sim. They contacted me saying they were switching me over to o2, so in future, I would be billed by o2 instead, but I also qualify for a few extra benefits for the same price.
Once that was activated, they then said – because I have Virgin Media and an o2 mobile Sim, I now qualify for a bonus speed to my Virgin Media home broadband. Not sure how that makes any sense and why I didn’t qualify before, but cool – free stuff.
However, my current router cannot handle the new speeds or something, so now I have to have their latest “Hub 3.0”.
When I received the package, I had a quick look through the instructions and it seemed as simple as plugging it in. The only thing of note was that when you think you are ready to connect your devices, you need to look at the lights on the Hub:
“When the Wi-fi light is on and the base light is solid white, you are ready to move on. The arrows may still be flashing green”
Instructions
I assumed the flashing arrows meant it was updating (but couldn’t see anything in the instruction manual), and when they stopped flashing after 1 hour (why does it take 1 hour to update!?), I had a stable green Wi-Fi light, stable green update arrows, and a stable yellow main light. So what does that mean? it doesn’t match their description.
After a minute, the green update arrows and green wi-fi light went out, and I was left with a stable yellow main light and no internet connection. So I turned it off and on again. Same sequence of events happened.
So I reconnected my old router to check the internet was still working. It was.
The next day, I asked one of my colleagues (who I knew had Virgin Media broadband). He said he had a Hub 3.0 and his just has a stable yellow main light and had no idea what I was on about when I told him about the white light that the booklet mentioned. It was years ago when he had set his up, but he thought it was as simple as plugging it in, and away you go.
So after I logged off work, I plugged the “Hub 3.0” in again and got the same sequence of events. This time I went to the router’s IP page http://192.168.0.1/. Is it updating? Why so many updates?
I waited over an hour, but I was still stuck on the update screen. I turned it off-and-on again. Still says it is updating. But there’s no green arrows on the router itself. Can we trust the arrows?
I check Twitter and find a few people from various years with the same problem but some say that Virgin call centre staff resolved it – but didn’t say what the resolution was. Then there were some unresolved cases of people Tweeting into the void.
So since it was late, and I assumed Virgin’s call centre wouldn’t be available, I waited till the morning. I then plug it all back in, and call the number in the booklet:
“Connection issues? if you’re still having trouble connecting after following all the steps, waiting 30 minutes for your Hub to set up and making sure the connections are secure – call us on 0800 953 9500”
Instructions
I was greeted with an automated line asking me for my account number. I hung up and went looking for the letter. I call back, type in the account number, then it asks me if I would like to link my phone number to my account for faster calling in future.
That sounds great because I hate having to read out an account number, and go through the “security” checks. If I can bypass one or both of those, then it would be amazing. They always ask you for part of your memorable word and it always trips me up because I have only needed to call them 3 times in 9 years or something – so it is easy to forget. I was convinced I knew it, and this would test out my thoughts, so I went through the process of trying to link it.
The automated voice instructed “press the key that corresponds to the first letter”, so the 2 key would represent A, B, or C. Maybe not so secure when there’s ambiguous answers. I typed the 3 numbers in, and apparently it was wrong. So I hung up.
I went to the website, account details, “change memorable word”. You have to choose a word between 8 and 10 characters long, but it’s not quite a word because it needs 1 number. With that level of specific criteria, it probably makes it less memorable too. So I type in 9 characters and a number to get 10 characters in length. Apparently it didn’t match the rule “8-10 characters long”!? So “8-10” actually means 8 or 9?
Eventually I managed to set it to something slightly memorable, so call back. Enter the “Account number”, “memorable word”. Right, as long as I call using this mobile number, it should get me straight through in future.
Right, can I speak to a human now? no.
The automated voice says they know I have been sent a new Hub and if I press “1”, they can send a signal to activate it.
WHAAAAAAAAAAAAAAAAAAAAAAAAT!?
Me, raging
The instructions never said that. It said to wait 30 mins for a solid white light and wi-fi light, then only call if there’s connection issues. Yet this number is an automated line that is VITAL to call.
So I press “1”. The voice says it “may take 1 hour for the connection to activate”.
What!?
Super fast broadband, like 264 mbps and you are saying it takes 1 hour to transfer 1 signal to tell the router it is valid? What the hell. I was supposed to be working and thought I would be offline for 15 mins.
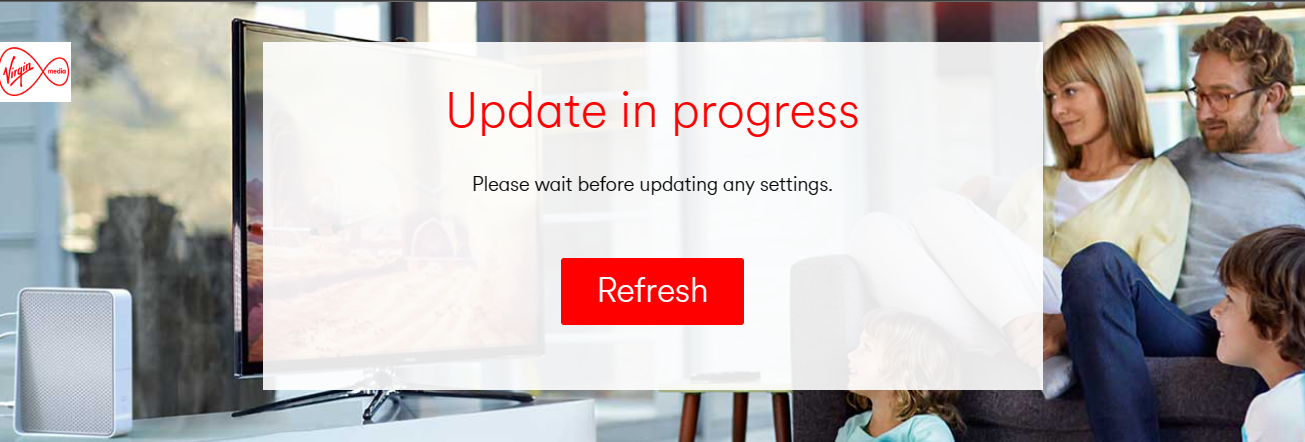
After waiting 1 hour, there’s still no connection. I waited another 15 mins. I checked the router settings page; “Update in progress”. It’s either lying, or completely broken.
So I called the number again to see what would happen. The automated voice tells me my account number is linked to my phone, so I press “1” to accept. Now I have to enter 3 letters from my memorable word. At least not entering the account number is convenient. I put my letters containing the account number in the drawer; I won’t be needing those again.
The automated voice tells me that the “signal” had failed to activate my router, so I have to be passed onto a human. I connect straight away, and first I need to state my name. Now I need my account number. WHAT!? I can’t have gotten this far without my account number which I had linked to my phone. So I scramble to get the papers out of my drawer so I can read off the account number. Now I need to specify 3 characters from my memorable word. (╯‵□′)╯︵┻━┻
If it is a challenge to make a calm guy like me turn aggressive, then this is certainly the way to go about it.
So I explain that I have this new Hub and it doesn’t work. She asks me what lights I see, and she says it should be working. I then get put on hold for a minute, then she says
“We haven’t registered this Hub at our end”.
Virgin call centre staff member
Brilliant. Why is that even a thing? The connection is coming through to the inside of my house (my old router works perfectly fine). Why do they need to authorise a device inside my house? They sent it to me too, so why wasn’t it automatically registered? You would think they would have the process perfected after all these years.
So after holding a bit longer, she said she would then send the signal but it may take an hour. She then asks if “I am happy with the resolution?”.
“Eeeer. Dunno. If it works, then yes. If it doesn’t then no.”
Me, uncertain
“It will work, sir. We will send you a text message when it is activated.”
Virgin call centre staff member
The connection actually came on after 1 minute.
1 hour 45 later: Virgin via text: “We’ve activated the new Virgin Media kit“
Here’s a list of things that are dumb:
If you send someone some new hardware, make sure it is registered on your system
If it requires the customer to make a phone call, make sure it is clear in the instructions
The phone number should also state when the line is open, and if it is automated or not.
If there’s lights on the hardware device with different meanings – put them in the instruction booklet
Don’t tell the user they are looking for a white light, when it is actually yellow.
Don’t make a page stating “Update in progress” when the status is “Unregistered device”
If there is an Update process, explain to the user what this means and how often it should occur, and how long it should take. What if I turn off the device whilst it is updating? Does it become “bricked”?
Don’t send a text 1 hour 45 minutes late.
Don’t tell the user they can register the account number to their phone, then ask them to read out the account number.
Don’t say you can create a memorable word of 10 characters, then tell them they cannot.
As a human, don’t ask for 3 letters of a memorable word, and when the customer gets it wrong, ask for 3 different letters. There’s a good chance you could piece what the full word is by putting together the answers. I assume the call-centre staff cannot see the full word, but it wouldn’t surprise me at all if they could.
There must be a better way of activating a router than via signal that takes up to 1 hour. I assume there’s some serious leeway here, but it’s not good to keep a customer waiting that long before calling support again.
When we add new, optional features, we often put in a flag to enable or disable the feature for certain users. This allows us to slowly roll-out the feature, or only enable it for customers that pay the premium. If there’s problems, you can also disable the feature quickly without pushing out a new version of our software.
One team had decided to rename their module, and therefore were updating the configuration flag’s name.
A lead developer, who reviewed the change, questioned if they could do that without running into incompatibility issues. The project team’s lead stated:
“No, we have the feature validation at source and target separately before we do anything. So, there should not be any compatibility issues.”
Project Lead
However, I was convinced the lead developer was correct. We have multiple versions of our software deployed, but we only have one version of the Configuration Manager tool.
So let’s say in Version1, the new module is called “User Manager“, but in Version2 they want the module to now be called “Staff Management” – and so they update the main software and the Configuration Manager tool to use this new name.
When we use the Configuration Management tool for new users that are using Version1, we update their config to use the new name “Staff Management“, however Version1‘s software will be looking for “User Manager” and will not find it, so will think the module is disabled.
Existing users on Version1 with the old flag in their configuration will work as normal, but it won’t work for new users. For Version2 users, the Configuration will have to be redeployed since their config will have the old name, but Version2 will be looking for the new name.
If the Configuration Management tool used ID’s rather than matching on text; it wouldn’t be a problem, so we have screwed ourselves over there. Matching on text is rarely a good idea due to possible spelling mistakes, case sensitivity (is “User Manager” the same as “user manager“?), and usually less efficient matching on something else like a number ID.
I spent a while trying to think of ways around this issue. Ideas that I thought of involved writing complex database scripts, running scripts outside the release process and getting other people involved. But then I think all my ideas still wouldn’t solve the incompatibility issues and it seemed way too much work for something trivial.
The team were adamant they wanted to rename it though, but it didn’t really matter too much. Only our staff see the Configuration Management tool, and we can update the main software so the users see the new name. It just adds confusion if someone tells you to enable “Staff Management” but you can’t see the option, so they have to correct themselves and ask for “User Manager” instead.
I would have thought the project team would have ran through different scenarios to test if their idea was feasible for new and existing users. But even after questioning it was feasible, they were adamant there wouldn’t be any compatibility issues so I had to explain the scenarios to them.
Becky is a Software Tester with maybe 15 years testing experience, so you think she’d know what she is doing.
When I was a Tester, I quickly learned what the developers wanted in order to help you. The Message and Stack Trace is mandatory if the software crashed, but it’s always great if you can explain what you were trying to do to “set the scene”:
What you expected to happen,
and what actually happened.
Then, if possible, state specific steps to consistently recreate the issue. This is what Developers need to fix a bug, but the same information is great if you want help after failing to configure a server/feature etc.
In this situation, Becky had what sounded like a straight-forward task, and under normal circumstances, you could just log in to the software, fill in a few fields and click save.
She posts on Slack for help, and states she thought this task would be simple but it’s “not the case”. Then says with “Alan’s help, I’ve changed a config file”, and she was trying to use a configuration program but was “unable to connect”.
I’m reading her message and thinking “why has she changed this config file?”, and “what has the connection error got to do with anything else she said in the message?”. She should be able to do all this using our software.
So I message Alan to translate what she said. He did explain it wasn’t that simple, and so they were doing this configuration an alternative way. He said the current problem was just connecting to the server, and he had told her to log a ticket with the Networks team. He said after that, he would carry on helping her.
So I reply to her message on Slack, stating that Alan is still helping her.
She then says that she “knows there is knowledge within the team and didn’t want to take up any more of Alan’s time”.
I thought she was just wasting other people’s time by trying to get other people unnecessarily involved. Alan had helped until this blocking issue occurred; which Becky needed to get the Network’s team to sort out. There’s no point wasting other people’s time.
Since I had already invested some time into it, I decided to ask her some questions. I wanted to know the IP address of the server she was having trouble with, the IP address of the system she was initially configuring, and a database ID so I could actually see if she had the data in the correct tables.
She only answered 1 of my questions, and her response was a slight rephrasing of the thing I questioned. So she wants help, but won’t give me the info in order to actually help. At no point did she say that Alan had instructed her to log a ticket, so she wasn’t even following what Alan told her.
I find that there are a lot of Software Testers that fail to give you enough information to do your job. Somehow they think you can magically work out what they intended to do, and work out what the problem is with barely any information.
At university, the operating system we used was Linux, and although there was a graphical user interface, we were always encouraged to use the command line. For some people, this was very uncomfortable, and often people didn’t really understand the commands they were typing.
Sometimes we were assigned group coursework, so someone took the lead, and then changed the permissions on their folder so that their team could access it.
The thing is, people didn’t understand what they were typing, or cut corners. This meant that some people gave access to EVERYONE to access that folder. Others granted access for EVERYONE to ALL FOLDERS.
I reported this as an issue because someone could then grab people’s code or written reports, change a few lines and submit it. Easy. It could even be a privacy concern if people have personal files saved on the university system. If you were given permissions to modify, you could delete their files.
The IT guys told me that changing permissions was an allowable feature and it is up to each student to grant the correct permissions, so they rejected my concern.
They could have at least put out a mass email telling people to check in order to alleviate the potential damage.
The good thing was that when I wasn’t sure of what to do on future coursework, I could then check this new source of information for inspiration. 😀
Recently, we were running into Out Of Memory issues with our software. A developer had identified that a feature which launched an embedded browser was using up quite a bit of memory, and we could move it into a separate process which would have its own memory allocation.
We followed his recommendation, so we moved the browser into a separate process and released this software (which I will denote “V1”). This caused an issue because the dll wasn’t built with the correct settings. We needed a quick fix due to the number of complaints from our users. It would be easy to fix, but due to the Testers stating it would take a few days to test it again, the managers told us to simply revert it and give the users the memory issues again (so this is “V2”).
We then fixed it, but since we had more time, we decided to implement a configuration switch so that if it went wrong, we could just disable it without having to release a new version. I made a small refactoring to get the configuration switch working, but I made a small mistake in the constructor which caused a crash in one of the places where the browser is launched. A Tester had found it late in his testing. I came up with a fix, but then we got called into a meeting to discuss what we needed to do. Unfortunately, my new fix would require a lot of the testing to be redone. The “refactoring” I did was brought up for discussion, and an experienced developer said that my way of doing it wasn’t the way he imagined. All the managers on the call trusted his judgement and felt I had gone a bit overboard, so they insisted I redo it.
So I had another look and couldn’t see how I could possibly do it without refactoring at least slightly. I did the best I could which I’d say was actually ~90% identical, apart from it was clearly worse from a code-design perspective. I showed it to the experienced developer and he said that was how he imagined it. I was baffled, but this is what the managers asked for. The release got delayed a week because the tester had to retest everything. So in the end, we had just wasted days of time to make the code worse. Brilliant. If we had gone with my original fix, it would have taken the same amount of time, but the code would be better.
Additionally, we did highlight we couldn’t test all the third-party suppliers we integrate with, so we had “low confidence”… or there’s some uncertainty at least. However, the Directors got involved and they wanted it out. So out goes “V3”.
There was a problem with just one of the third-party suppliers, but for some reason, Support left the feature enabled for several hours, when they could have reverted it with my Config Switch. This led to many complaints (yet again), and therefore panic from the management. When it came to disabling it, despite being able to disable it for particular users, they turned it off for large groups.
We rollout our changes in phases, so the Software Delivery managers wanted me to rollback the changes once more before releasing to the next group of users. I asked why we couldn’t just use the Configuration Switch, and the response I got was “we don’t trust Deployment to turn the feature off. What if they miss some users?”
Well, when those users complain, you just switch the Configuration Switch to “off”. If we rollback again, then we are back to square one; where users can encounter the memory issue.
What is the point in coding a Configuration Switch if they won’t use it? I did point out the way the Configuration Tool works is that you could set the configuration ahead of time (the previous software version will just ignore the extra config), then when the users get the new version, then the updated version would use the configuration file as intended. So with a bit of persuasion, that’s the option they went for. However, they turned it off for every user, even if it wouldn’t have caused problems for them.
When will they turn it back on?
Conclusion
It was actually a good idea to use a Configuration Switch. If the feature doesn’t work properly, you can quickly revert to the old way (well assuming your new changes don’t unintentionally break the existing feature). Obviously, you need to trust the Deployment team to actually use it correctly.
Colin went with a Configuration Switch for his recent project. How did he get on?
“The bug can’t be introduced by our project because it is switched off on live”. 5 mins later… “This is definitely code that we changed”
When we entered lockdown, there was a small project that was identified as urgent, and very helpful to our users due to the current situation. Originally, they estimated a simple change. So we make a change to one file. When testing it, we realise it didn’t send the information in the outbound messages to a third party. So we made further changes which were a few day’s work.
We then had a meeting with a few different types of managers. They wanted to know about our progress and they wanted estimates to finish the project. I thought it would only take a few weeks to test. However the Tester said it would take 3 months which I think he was just being extreme to cover his back. He did explain it was more complex than I had thought, but still – it was clearly over exaggerated. The Managers didn’t like the idea of having a Tester tied up for that long, so the project went “on hold”.
Months later, I was invited to a meeting to restart the project. A Project Manager was ranting that there was a financial incentive to get the feature out by the end of the year (2020), but if we deliver it late, then we miss the bonus. Even if we restarted straight away, we had left it too late – there was no way the testing could get done, and deploy in time to meet such a deadline.
The Tester stressed that my solution is just a prototype and needs to be reworked. In reality, it was fine as far as I was aware, but he was just buying extra time if we needed it. It was the Testing side of things that needed the focus. We needed to test these extra configurations, but a prerequisite was that we needed to understand how they were set-up.
I couldn’t really do much work until the Tester had done this extra testing to see if my solution covers all the different configurations he had come up with. However, the Tester was busy with some other work so he couldn’t do that for a few weeks. A few weeks later, a Product Manager messages me to ask when the project started. I delivered the bad news: “It hasn’t”.
A few more weeks go by, and we have a meeting with a new Project Manager. So we discussed the story so far with him. It was also announced that the Tester (who has all the knowledge about this project) would only be partially available – so needs to pass on his knowledge to another Tester.
Another week or so goes by and another meeting was arranged. We have a new Project Manager.
Ridiculous.
She starts making all kinds of demands about having all the usual Agile process. (User Stories with estimates etc). However, it’s a weird project because we have basically done the development and we just need to test. All this process seemed a bit overkill to us.
We had another “Project Kick-Off” meeting, and the Tester asked the Software Architect about setting up all these different configurations. The Architect then said the Tester had misunderstood and there was actually only 1 configuration.
This meant the testing time had been drastically slashed – you know; the exact reason why the project was delayed in the first place. So all these delays, extra meetings talking about the delay, all the meetings to rearrange the project; none of them actually needed to happen. We could have just completed the project when it was first assigned, additionally collecting that financial bonus.
I was talking to one of our Test Environments Engineers and he was absolutely raging. He said he had spent the entire day looking into a ticket someone logged that stated they could no longer connect to their server.
The Engineer said he was panicking because he thought they had been hit by a malicious virus. All the services on the server had been disabled which is why you couldn’t connect to it by standard means.
After a bit of investigation and quizzing the person that logged the issue, they admitted to some key information. The server had been slow, so they had disabled every single service on the server in an attempt to speed it up…then rebooted it. But since many of the services are vital for the server to function, or at least connect to the server; then the server was pretty dead.
The Engineer was raging that the person that logged it failed to mention this on the ticket, which would have been vital to work out what was wrong and how to fix it. Surely he realised it was his fault that the server was dead, it’s just that he wanted to try and cover up his mistake.
A new customer reported a particular feature was broken. This feature used a web browser (Chromium) to work.
A developer spent ages trying to work out what was going on and realised that the site had an invalid proxy script. The invalid script was causing a crash within Chromium, rendering this feature completely unusable.
Due to a typo in their proxy script, their proxy wasn’t blocking access as described by the script; it was basically “anything goes”.
The developer told them how to fix it, and we thought it would be case-closed. However, now that the proxy blocked access to websites as defined by their IT department, their employees started complaining.
Instead of the IT department:
tweaking the rules,
Disabling the script completely
or simply informing their staff that these sites were blocked according to their company policy
They decided to revert back to the original broken script. This obviously made our software break again.
Really, it was a problem with Chromium, the software used in Google Chrome and now Microsoft Edge. Obviously, the workaround is to actually set a valid proxy script, but they decided to be awkward.
There’s a team who chose to set-up a generated report every time a code build was triggered. This report will show the usual static analysis checks like Code Coverage, “Code Smells”, bugs etc. It was encouraged that other teams should set this up too; so we were told to contact Rory who was leading this initiative.
I took responsibility for setting this up for my team, so I contacted Rory who sent me a link and said “just follow the instructions”.
I look at the instructions and they seemed to be for setting up a new instance of a Report server, rather than making your build process utilise the existing Report server. Common sense told me he had sent me the wrong link. I asked him again.
He reiterates: “It’s really easy, just follow the instructions”.
I felt Rory was messing me about, so I asked another colleague who was also setting it up for his team. He told me that with Rory’s link, there was only one link within that page which showed you some sample configuration. Every other step listed wasn’t relevant. Yup, Rory was messing me about.
Once set up, you then get a “permission denied” because Rory needs to give your team explicit permissions to contact the Report server. Of course, even though I told him I was setting it up at the start of the day, he hasn’t bothered adding me to the authorized users. Instead, he then wants me to send a request on his Slack channel before he will grant me access.
The thing is, several other teams also needed to set it up, and they went through a similar process of being messed about.
Why didn’t he write some custom instructions? Most of the configuration could just be copied from one team to another.
Also, he always waited until teams were stating they were getting the “permission denied” before granting them access. Why couldn’t he just add them when they initially requested the instructions?